Python在抓取和分析网页方面很强大,所以现在有很多使用python实现的各种各样的网络爬虫。我以前做过一个app北京房屋交易查询用来展示北京房屋的交易情况,在app的内部使用java实现对网页数据的抓取,现在感觉做的比较笨。现在使用python来抓取试试。
1.确认抓取网址和内容
数据是从北京市住房和城乡建设委员会的网站上抓取的,地址为http://www.bjjs.gov.cn/bjjs/fwgl/fdcjy/fwjy/index.shtml。打开网址后我们会看到前一天北京新房及二手房的交易量等数据, 这些数据是我们想要抓取的,如下图所示: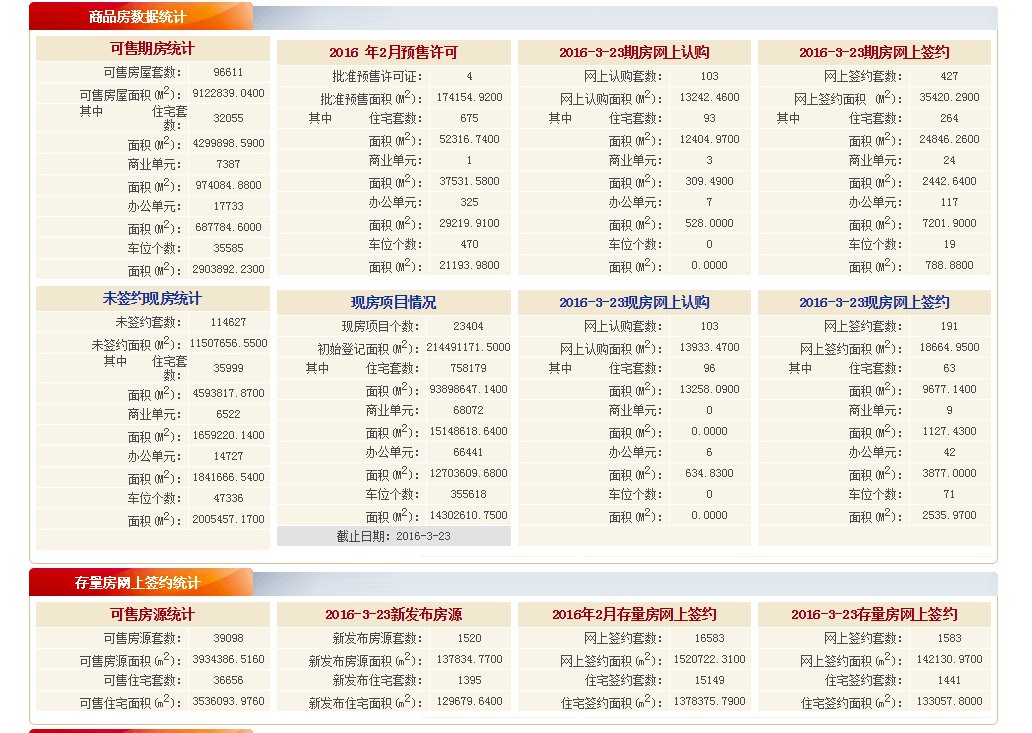
如果是Chrome浏览器,按F12后点击Souces标签就可以看到网页的源码了,我们想要抓取的数据也都在这里面。可以将网页源码先复制到一个文件中,开发测试的时候先从文件读取内容,这样可以节约很多访问网络的时间(这个网站貌似不是很稳定)。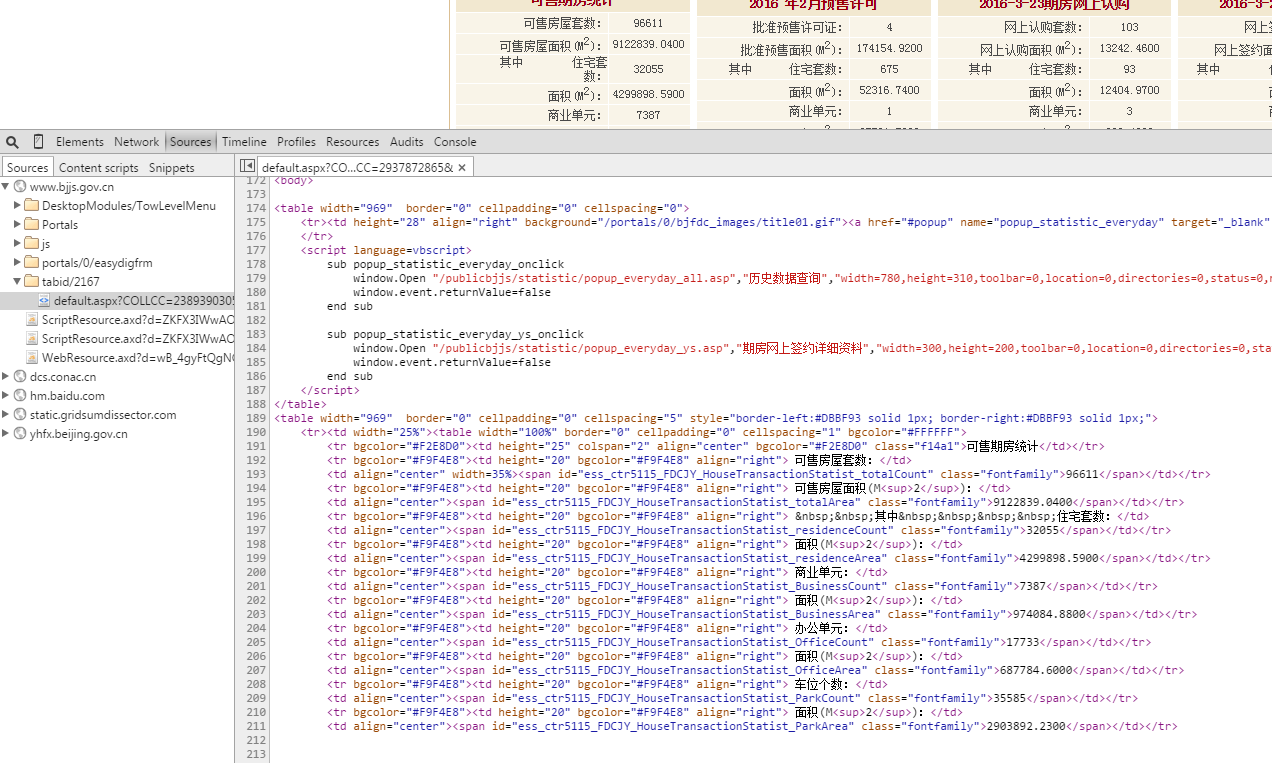
2.访问网络得到网页源码
网址和内容都确认好了就可以通过get请求获取网页源码。访问网络我们使用urllib2模块,非常方便好用。首先import urllib2,然后写一个get方法,去get给定的网页内容:1
2
3
4
5
6
7
8
9
10import urllib2
def get(self, url):
request = urllib2.Request(url);
try:
response = urllib2.urlopen(request)
read = response.read()
return read
except urllib2.HTTPError, e:
print'Get content failed:' + e.code
return
3.抓取数据
抓取数据当然要使用正则表达式了。关于正则表达式网上有很多相关的资料,想要系统的学习可以看一下这个网站讲的不错。从网页中抓取数据的正则表达式一般比较长,我们很难一次就写对(大牛请忽略),那就写一段就运行一下试试吗?效率未免也太低了。好消息是一般的文本编辑器都支持正则表达式搜索功能,如android studio,按ctrl+f打开搜索框后,选中右边的Regex就可以在搜索框中输入正则表达式来搜索内容了。我们提前将网页源码保存成一个文件并在android studio中打开,一边输入正则表达式一边就可以即时地查看到我们所输入的正则表达式的匹配情况,这样就可以很快地写出我们所需要的正则表达式。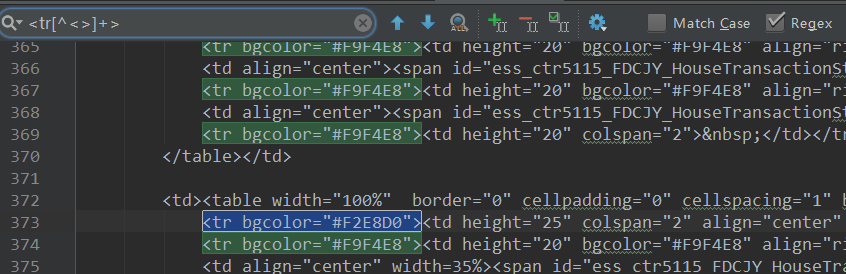
由于商品房和存量房的数据格式不同,所以我们需要写两个正则表达式分别来抓取商品房和存量房的数据。在正式抓取之前我们还需要将原始的数据处理一下,否则我们抓取到的数据里面可能会包含一些 的标签。在python中使用正则表达式要引入re模块,然后使用sub方法将所有的 都替换成空格符。其中注释掉的内容是用来读取提前保存好的网页源码,在开发测试的时候使用,等功能都开发完毕后就可以去掉这部分代码直接从网上获取源码。1
2
3
4
5
6
7
8
9
10
11
12
13
14import re
def read_content(self):
print'Get content from Net.'
# with open("content.txt", 'r') as f:
# content = f.read().decode('utf-8')
content = self.get(self.Url).decode('utf-8')
if content:
# remove  
pattern = re.compile(r' ')
txt = pattern.sub(" ", content)
print'Get content success.'
return txt
else:
return
1.抓取商品房数据
我们知道网页的源码里面包含了很多html的标签,如何正确快速地匹配这些标签是抓取数据的关键。我们可以使用一个表达式<[^<>]+>来匹配所有的html标签,这比<.*>效率要高的多。我们先来看一条商品房的数据源码:1
2<tr bgcolor="#F9F4E8"><td height="20" bgcolor="#F9F4E8" align="right"> 可售房屋套数:</td>
<td align="center" width=35%>77728</td></tr>
我们所需要的数据就是“可售房屋套数”和“77728”这两个数据,所以我们用一条表达式将其匹配出来:1
'<tr[^<>]+><td[^<>]+>([^<>(:]+).*</td>\s+<td[^<>]+>([^<>]+)</td></tr>'
我们需要抓取出所有的商品房数据,所以我们使用了findall方法一次就可以返回所有需要的数据。需要注意的是我们要去掉里面中文标点冒号,所以正则表达式后面必须加上.decode( “utf8”),否则是去不掉的。同理如果由其他的中文标点都可以这样去掉。1
2commercial = re
.findall(r'<tr[^<>]+><td[^<>]+>([^<>(:]+).*</td>\s+<td[^<>]+><span[^<>]+>([^<>]+).*</span></td></tr>'.decode( "utf8"),content)
2.抓取存量房数据
还是先看一下存量房的数据:1
2
3
4
5
6
7
8<tr bgcolor="#f9f4e8">
<td align="right" bgcolor="#f9f4e8" height="20">
可售房源套数:
</td>
<td align="middle" width="35%">
17576
</td>
</tr>
在这里我们需要抓取的数据是“可售房源套数”和“17576”,同上面一样使用findall抓取出所有的数据:1
stock = re.findall(r'<tr[^<>]+>\s*<td[^<>]+>([^<>(:]+).*\s+</td>\s+<td[^<>]+>\s+([^<>]+)'.decode("utf8"), content)
4.整理数据
数据都抓取到了,下面将数据都整理一下,为了便于使用的时候解析,我们将所有的数据整理成一个json字符串。
首先看商品房数据,里面有70条数据,而且都有一定的规律性,那就用一个循环将所有的数据整理出来,放在一个dict里面1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20commercial_bean = {}
if commercial:
items_queue = []
for i in range(8):
item = {}
detail = {}
item['count'] = commercial[i * 10][0] + ":" + commercial[i * 10][1]
item['title'] = self.commercial_title[i]
item['area'] = commercial[i * 10 + 1][0] + ":" + commercial[i * 10 + 1][1]
detail['houC'] = commercial[i * 10 + 2][0] + ":" + commercial[i * 10 + 2][1]
detail['houA'] = commercial[i * 10 + 3][0] + ":" + commercial[i * 10 + 3][1]
detail['comC'] = commercial[i * 10 + 4][0] + ":" + commercial[i * 10 + 4][1]
detail['comA'] = commercial[i * 10 + 5][0] + ":" + commercial[i * 10 + 5][1]
detail['offC'] = commercial[i * 10 + 6][0] + ":" + commercial[i * 10 + 6][1]
detail['offA'] = commercial[i * 10 + 7][0] + ":" + commercial[i * 10 + 7][1]
detail['carC'] = commercial[i * 10 + 8][0] + ":" + commercial[i * 10 + 8][1]
detail['carA'] = commercial[i * 10 + 9][0] + ":" + commercial[i * 10 + 9][1]
item['detail'] = detail
items_queue.append(item)
commercial_bean['items'] = items_queue
存量房的数据也不少,有16条而且也有规律性,也用循环整理出来,也放在一个dict里面。使用strip()消除多余的空格符。1
2
3
4
5
6
7
8
9
10
11stock_bean = {}
item_queue = []
for i in range(4):
item = {}
item['tit'] = self.stock_title[i]
item['cou'] = stock[i * 4][0].strip() + ":" + stock[i * 4][1].strip()
item['area'] = stock[i * 4 + 1][0].strip() + ":" + stock[i * 4 + 1][1].strip()
item['cou2'] = stock[i * 4 + 2][0].strip() + ":" + stock[i * 4 + 2][1].strip()
item['area2'] = stock[i * 4 + 3][0].strip() + ":" + stock[i * 4 + 3][1].strip()
item_queue.append(item)
stock_bean['items'] = item_queue
最后将commercial_bean和stock_bean放入一个dict里面,并使用json模块将所有的数据转化成一个json字符串。1
2
3
4
5import json
self.jsonBean['c'] = commercial_bean
self.jsonBean['s'] = stock_bean
jsonstr = json.dumps(self.jsonBean).decode('unicode_escape')
print jsonstr
打印输出最后的json字符串检查一下是否是我们想要的内容。
5.上传到LeanCloud
数据整理好了后就可以上传到LeanCloud保存起来,这样我们就可以有历史数据让app查询,并且不需要重复地去抓取数据。关于使用LeanCloud的详细说明可以看官方的文档。
我们定义一个方法用来上传数据:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18def update_data(self, data):
print ('Update data to server')
JSON_TNAME = "JSON_TNAME";
JSON_DATE = "JSON_DATE"
JSON_TIME = "JSON_TIME"
JSON_CONTENT = "JSON_CONTENT"
leancloud.init('yourid', 'yourkey')
BeanObj = Object.extend(JSON_TNAME)
leanObj = BeanObj()
leanObj.set('JSON_DATE', self.jsonBean['c']['date'])
leanObj.set('JSON_TIME', int(self.jsonBean['t']))
leanObj.set('JSON_CONTENT', data)
try:
leanObj.save()
print 'Update success.'
except LeanCloudError, e:
print 'update failed' + e
6.实验
现在运行一下试试吧,一切顺利,数据成功抓取到并上传到LeanCloud服务器了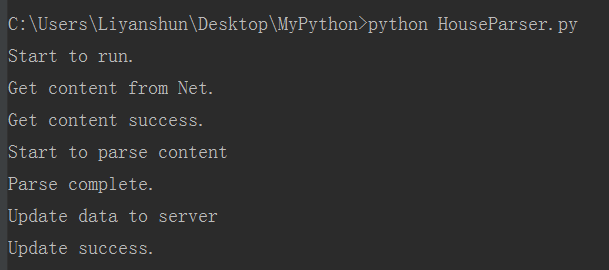
让我们去服务器上看看,果然有了我们抓取到的数据
最后通过app来访问这些数据,能正常显示。至此我们的抓取工作就完工了。关于本文中的详细代码和保存的网页源码请见Github